
تحلیل تخصصی سخت افزار از معماری NVIDIA Turing
در زمان معرفی کارت گرافیک های NVIDIA GeForce RTX 20، موارد فنی بسیار به همراه "تحلیل کامل سخت افزاری" از این محصولات را برای شما عزیزان منتشر کردیم؛ در روز گذشته نیز اجازه انتشار برخی از اسلاید های مهم در زمینه محصولات فوق، از سوی سازنده داده شد و بدین ترتیب متوجه شدیم که انویدیا ضمن بالا بردن چشمگیر قابلیت اورکلاک، از کلید اورکلاک آنی نیز در این محصولات استفاده کرده و این کلید با کمک شرکای این شرکت تکمیل خواهد شد. این مطلب دومین "تحلیل فنی-تخصصی" در زمینه کارت گرافیک های جدید این شرکت است. در این مطلب به سراغ برخی دیگر از قابلیت های معماری نوین Turing خواهیم رفت تا بدانیم چه در دل این سیلیکون های عجیب و توانمند می گذرد. با "سخت افزار" همراه باشید.
استفاده از هسته های INT32؛ در ابتدا به سراغ هسته های INT32 می رویم. انویدیا برای نخستین برای از تکنیک هسته های INT32 استفاده کرده است؛ تا کنون متوجه شده ایم که هر هسته دارای فواید اختصای خود خواهد بود؛ از CUDA گرفته تا RT و Tensor. اما داستان هسته های INT32 به بخش ستاد مشترک باز می گردد. هسته های INT32 و یا به عبارت ساده تر، این واحد ها برای این منظور طراحی شده اند که به صورت همزمان قادر به پردازش داده های "اعشاری" و "اعداد صحیح" (Floating و Integer) باشند. برتری GPU به نسبت CPU در این جمله خلاصه می شود که به دلیل داده های همگون و مشابه، سرعت GPU بسیار انقلابی تر از CPU، در داده های گرافیکی است. اما چه می شود اگر داده های مشابه در اعداد صحیح و اعشار به طور همزمان رندر شوند؟

پاسخ ساده است؛ سرعت پردازش به طور چشمگیری بالا رفته و شاهد کاهش وقفه ها هستیم. انویدیا معتقد است که این عمل موجب افزایش سرعت پردازش در اعداد اعشاری، تا 36% می گردد. رندر موازی در INT32 به پارامترهای دیگر از جمله حافظه کش مشترک L1 و کش Texture نیز وابسته است. با وجود پیشرفت های ذکر شده در معماری، تحویل توان و INT32/FP32، انویدیا موفق شده است تا عملکرد هسته های CUDA را تا حداکثر 50% به نسبت نسل پیشین (Pascal) افزیش دهد.
پیشرفت در ساختار سایه ها؛ اینک نوبت به معرفی برخی از فرآیند های مهم این حوزه رسیده است. در این بخش، اتفاقات بسیاری روی داده است که هر یک می توانند به مقاله ای مجزا مبدل شوند؛ اما به چند مورد آن اشاره خواهیم کرد. Mesh Shading یک الگوریتم جدید سایه زن است که از آبجکت های بیشتر در هر صحنه پشتیبانی کرده و امکان ایجاد سایه های هندسی را خواهد داشت. تکنیک دیگر با نام Variable Rate Shading، به اختصار VRS، وظیفه کنترل توسعه دهندگان بر نرخ سایه سازی را خواهد داشت؛ VRS از افزایش سایه ها، بدون کمک به جذابیت صحنه جلوگیری می کند.
سومین تکنیک مهم در این حوزه Texture-Space Sharing نام دارد؛ ذخیره سازی نتایج الگوی سایه در حافظه، بدون نیاز به تکرار. آخرین تکنیک مهم این بخش نیز Multi-View Rendering یا MVR نام دارد که تقسیم هدف دار رندر به بیش از یک زاویه را بر عهده دارد.
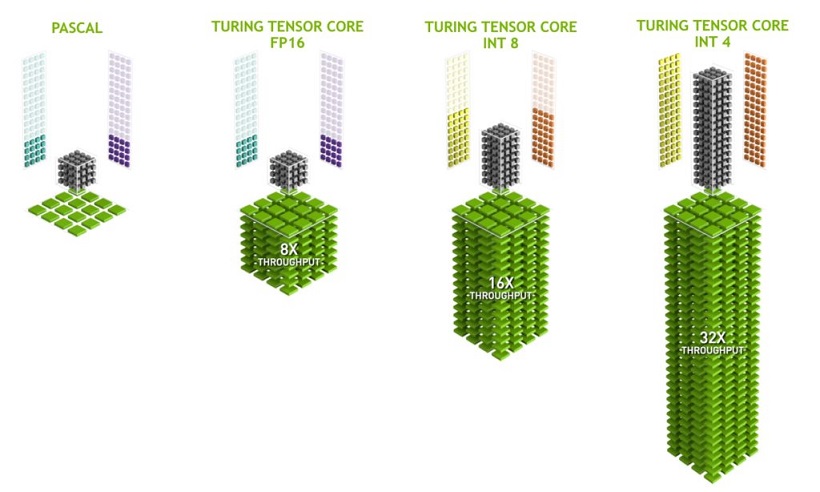
در بحث فشرده سازی حافظه، باید بگوییم که AMD و NVIDIA مدت هاست که به دنبال یافتن الگوی های مناسب برای این منظور هستند. NVIDIA از یک تکنیک خاص در Turing-GDDR6 بهره گرفته است که البته اطلاعات زیادی از شیوه عملکردهای آن نیافتیم؛ اما به گفته این شرکت، فشرده سازی تورینگ تا 50% بیشتر از Pascal ها است که این مسئله به معنی "پهنای باند" بالاتر و پردازش گسترده است. شایان ذکر است که AMD نیز از یک تکنیک مشابه در کارت گرافیک های Vega استفاده کرده است.
موتور تصویری (Display Engine) یک بخش تنومند و حرفه ای، اینبار حتی با رندر 8K هم بیگانه نیست. این موتور از درگاه جدید DisplayPort 1.4a با نرخ 8K بر روی 60 هرتز، حمایت می کند. جال است بدانید که یک کارت گرافیک تورینگ می تواند دو نمایشگر 8K با فرکانس 60 هرتز را به صورت همزمان تغذیه نماید! این مهم از طریق درگاه های DP و USB-C صورت می گیرد. ویژگی های جدید موتور پیشرفته NVENC رمزگذار، امکان پشتیبانی از H.265 با نرخ 30 فریم در 8K را ممکن می سازد. NVDEC با HEV YUV444 10 / 12b HDR، H.264 8K و VP9 10/12 HDR سازگاری کامل دارد.

در بخش تقلیل سیلیکونی، تا کنون 3 سیلیکون از ریخته گری TSMC به بیرون کشیده شده است؛ TU102، TU104 و TU106 که بازیگران اصلی تا پایان سال 2018 هستند. این سیلیکون ها به ترتیب دارای 18.6 میلیارد، 13.6 میلیارد و 10.6 میلیارد ترانزیستور فعال هستند. برای مطالعه بیشتر در این زمینه می توانید به مطلب "درون سیلیکون های جدید انویدیا چه می گذرد؟" مراجعه نمائید.